(cross-posted to LinkedIn) To work for a company that gets acquired is a dream for many, but one of the downsides is the potential for staffing cuts–especially for someone who’s only been there a few months. Which is to say: I’m open to work and actively seeking a new role as a software architect. Several…
December 2022. There’s a definite sense that technology is accelerating. In the last six months alone, a handful of AI technologies have made incredible leaps forward in generating images and fluent human language interaction. Some days it’s a challenge to even keep up with the headlines. And yet, XML is still here. Even if in…
On the evening of November 17, 2022, I tweeted thusly: Lesson 1: Before you ask people to be hardcore-devoted to you, first you need to demonstrate that you have the qualities of a leader. In THEIR eyes, not yours. Lesson 2: Actually, you don’t ever ask people to be devoted to you. Instead, you inspire…
Carol Dubinko died peacefully in her sleep at 11:51pm Eastern on May 28, 2022. She was 73 years old. She will be missed.
Putting this out there for search engines, since someone will probably need it some day. Symptom: Dell Chromebook 11 inch 3380 would not turn on, despite being on charger all night. Same effect with different chargers, ruling that out as a cause. As soon as power was connected, the power light blinked at around once…
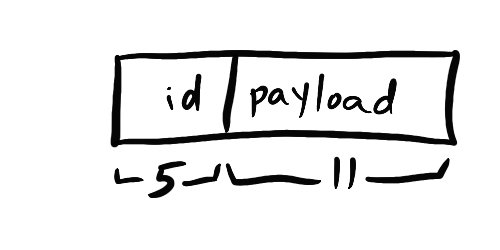
Thinking about bit operations on more humane terms.
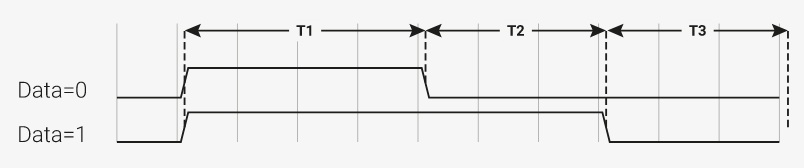
Code review of sample code running in a million places, with shocking results.

The three most important principles of note-taking
There are a bunch of complete build logs available for the Dactyl Manuform and similar mechanical keyboards, so I wanted to focus on the specific design choices I made and why. Huge hat-tip to Zack Freedman, in particular with this video, which served as inspiration that I could pull this off. Why a mechanical keyboard?…
Meetings, the cause and solution for all work-related problems, amirite? But seriously, arranging and then actually holding meetings with others, plus a dash of follow-ups, is how things get done in many professions, including software leadership. I have yet to find a single piece of software, or even a suite, that handles all the steps….
I’ve been a fan of David Mertz since I devoured (and practically lived out of) his book Text Processing in Python. So I was thrilled at the chance to be a technical reviewer for his new book Cleaning Data for Effective Data Science: Doing the other 80% of the work with Python, R, and command-line…
The Xiegu GSOC, marketed by Chongqing Xiegu Technology Co., Ltd, under the retail name Radioddity, gets billed as a “Universal controller” for ham radio. It boasts some impressive hardware, including a high-resolution touchscreen, dual-core processor, two different audio processors, and a custom-engineered control wheel smooth as butter. So naturally I had to tear it apart.
I’m not a UX expert, but I have opinions. Weather Underground is one of my most-used apps. It gathers data from thousands of neighborhood weather stations run by individuals. Here’s the new front page: The first thing you might notice is the large circular dial. That’s taking up a LOT of real estate here, and…
I recently joined LinkedIn as a Senior Staff engineer–an individual contributor role more senior than any of my previous roles. As such, I’ve been inundated with every manner of request for my time. Part of my journey toward handling this situation is writing up my thoughts. Let’s go. Does time work differently for “senior” engineers?…
If you haven’t been following Ted Nelson on YouTube, you’re missing out. Recently, he’s been posting a series of informational videos on the Xanadu architecture and concepts. Even more recently, he hosted a live Q&A session, taking questions from Twitter. Ted Nelson’s Channel What’s Xanadu, you ask? It’s the original concept for a hypertext system,…
If you played pinball in the 80s, you know about 16-segment LED displays. They existed in the narrow technology window after mechanical switches and alarm-clock-style 7-segment displays, but before full dot-matrix displays or full video were feasible with off-the-shelf computer hardware. There’s something geekily charming about these old displays. So naturally, I wanted to have…
I’ve avoided publicizing this until there was significant content out there. Announcing a new YouTube channel: Think LIke Tesla. This channel exists to celebrate a certain Serbian inventor/pop-culture figure and help YOU become a clearer thinker. In time, it will include everyday descriptions of Nikola Tesla’s patents and experiments, as well as fundamental ideas that…
I picked this up from The Plasma Channel on YouTube (which is worth more than a look) How to Measure High Voltage with Spheres A (somewhat) standardized way to measure high voltages is to see how big an arc can be established between two one-inch conductive spheres. The roundness of the spheres normalizes against surface…
When their hand was forced by hard evidence, Apple admitted what many people had suspected: they deliberately slow down older phones, in as little as a year. Their apology letter is a masterpiece of copywriting. But let’s have a closer look, shall we? A chemically aged battery also becomes less capable of delivering peak energy…
CQ, CQ, CQ. This is AJ6BD. I officially have a callsign. I can now legally broadcast on the amateur radio bands. I’ve been building radios since I was ten (really). I had plenty of help from my mentor, who taught me more than I realized there was to know about electronics, AC theory, signals, modulation,…
In the previous posting, I went over requirements for a DIY power supply build. Now on to the fun part–shopping! Case I wanted something fairly compact, but still nice looking. I ended up going with Jameco ABS Heavy-Duty Instrument Case. It’s a good quality build. In metric, it’s 200mm across, and 64mm tall, which is…
Building a power supply is a rite of passage for electronics experimenters. I grew up in an age where all power supplies, even “wall warts,” had heavy iron transformers. In the last decade or two, better power transistors have become available, making possible switching power supplies, which are much lighter. (Think of your laptop power…
Your shiny new iToaster complains when you plug it in: “This appliance has not been approved. Insert $0.25 to continue.†Net Neutrality explained.
Shall we speak for a moment about Amazon’s epic metadata problem? On amazon.com, search for “Bench Grinder‖a query with clear intent if there ever was one. Search by price low to high. Here are some items that appear in the results before a single piece of hardware you’d reasonably call a bench grinder… Water &…
Modern technology has exceeded my wildest dreams as a teenager struggling to build an electronics lab. With an Amazon.com order, one can have an entire electronics lab for next to nothing. As a teen, I paid a guy $100 for a used oscilloscope that took two adults to lift. These days, you can get a solid…
I’ve got a new book coming out. Check out some of the details in this short article. Overcoming Anxiety Join my mailing list for a free mini-course and be the first to hear about publication!
Here’s the manual I wish had been included with the 8x8x8 LED cube kit I picked up on Amazon. Technically there’s already a manual available if you know where to look, but it’s poorly translated and difficult to follow in places. There’s several very similar kits out there, but the LED assembly process is the same, as…
Another blast from the past, from the same era. This was a general-purpose gadget: a 5V power supply, plus bouncelsss switch, plus a variable frequency TTL square wave generator. This was one of my experiments with making my own circuit boards, starting with copper cladded boards, drawing on the circuit paths with an inert ink, then…
A blast from the past! While going through old stuff, I found this device, which I designed and assembled maybe 25 years ago. I never used it. I think it didn’t work on the first try, and I got distracted by other shiny things. Story of my life. I thoughtfully left my future self a…